바쁜 사람들을 위한 한 줄 요약
Lezhin Comics Feed(https://lezhin-rss.update.sh/)에서 구독하시면 됩니다.현재 동작하지 않습니다.
레진코믹스의 RSS를 제공하는 사이트를 만들었던 과정을 대략적으로 기록해 놓은 문서이다.
서론
레진코믹스(http://www.lezhin.com/)라는 웹툰 사이트가 있다. 여러 작가들을 데려와서 유/무료 웹툰을 서비스하거나, 이미 출판된 만화도 가져와서 볼 수 있게 했다.
레진코믹스 메인페이지. 세월호 1주기가 스크린샷을 촬영한 날이었기에 로고에 노란 리본이 달려있다.
네이버나 다음과 같은 포털에서 운영하는 웹툰 서비스와 비슷하지만, 적극적인 유료화 정책과, 나름 고수위(?)의 성인 컨텐츠를 제공하는 게 특징이다. 얼마 전에는 무슨 일이 있었는지 정확하게는 모르겠지만 레진코믹스 사이트를 방송통신위원회에서 차단하면서 이래저래 말이 많이 나온다. 나는 그거랑은 별개로, 레진코믹스에서 연재중인 레바툰이 이런 저런 커뮤니티 사이트들에 공유되면서 관심을 갖게 됬다.
나는 기본적으로 RSS 리더를 애용한다. 주로 들어가는 블로그나 사이트 게시판 등등을 가능하면 RSS로 구독하여 받아보고 있다. 물론, 네이버나 다음 웹툰도 그렇게 하고 있다. 다음 웹툰 서비스는 자체적으로 RSS 구독이 가능하고, 네이버 웹툰은 링크(홍민희라는 분이 만드셨다. 파이썬 행사에서 뵌적이 있는것 같은 느낌이…) 에서 구독할 수 있다. 그러나 레진코믹스는 RSS 구독을 지원하지 않았고, 다른 사람이 만든 구독 사이트도 없는 것 같았다.
Feed43(http://feed43.com/)과 같은 RSS 자동 생성 사이트를 이용할 수도 있었겠지만, 네이버 웹툰 구독 사이트처럼 한번 만들어 보기로 했다. 아마 시험기간이라 공부 말고 열심히 할 딴짓이 필요했던 것 같다.
지원하리라 마음먹은 대략적인 기능은 아래와 같다.
- 모든 구독은 RSS 2.0과 Atom 1.0을 복수 지원한다.
- 사실 별 차이점은 없지만, 그냥 둘 다 지원하기로 했다. 굳이 고르자면 Atom이 더 낫지만…
- 레진코믹스의 API를 이용할 수 있다면 실시간 생성, 그렇지 않다면 매 시간마다 생성해서 캐
- 개별 만화의 에피소드를 구독할 수 있다.
- 새로 추가된 만화를 구독할 수 있다.
- 왜냐면 새롭게 추가된 만화중에 보석같은 만화가 있을지도 모르니까?
- 구독할 수 있는 만화들을 보여주는 웹페이지를 만든다.
- 해당 페이지에서는 만화의 이름이나 작가의 이름으로 검색이 가능해야 한다.
현재는 위의 기능을 모두 구현했다. 만들어진 구독 사이트는 Lezhin Comics Feed(http://kb.update.sh/lezhin-rss/)에서 볼 수 있다. 레진코믹스 API를 사용할 수는 없었으므로, 매 시간 정각에 구독정보를 업데이트한다.
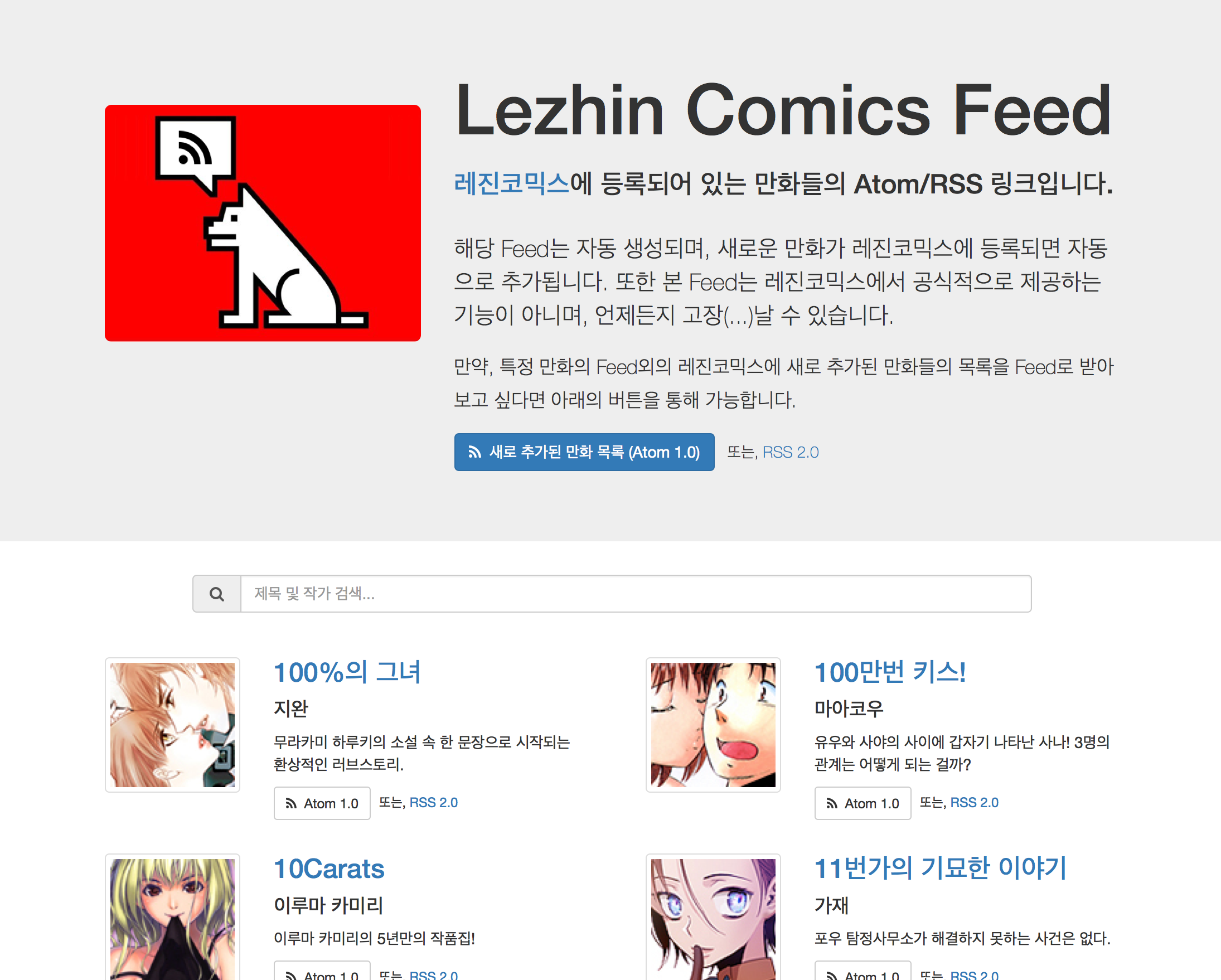
Lezhin Comics Feed 메인 페이지.
구현
만들기로 마음을 먹은 김에 바로 작업에 들어갔다. 일단 웹사이트를 만들어야 하는데, 내가 다뤄본 웹 프레임워크는 Python Flask밖에 없어서 선택권이 딱히 없었다. 어차피 빠른 개발을 하려면 결국 Python을 선택하긴 했을 것 같다
만화 및 에피소드 정보 가져오기
필요한 만화 및 에피소드 정보는 레진코믹스 웹사이트를 파싱해서 가져오면 될 것이라고 막연하게 생각했다. 그래서 레진코믹스 웹사이트를 켜서 이것 저것 봤는데… 분명히 동적으로 만화들을 처리하는데 ajax로 오고가는 데이터가 없었다.
가만히 보니, 처음 웹사이트의 html을 가져올 때, inline javascript로 만화나 에피소드 정보를 다 넣어서 받아오고 있었다! 이게 문제인게, 원래는 HTML을 파싱하거나, ajax call을 분석해서 API를 따라 쓰려고 했는데 이것이 불가능하다는 뜻이었다.
따라서, 적절하게 javascript를 파싱해서 만화 정보를 가져와야 했다. 우선은 requests 라이브러리를 이용하여 html을 가져와서, 이를 자체파싱-_-해서 사용했다. 이래저래 복잡하게 짤 수도 있겠지만, 딱히 퍼포먼스가 문제될 것 같지는 않았기에(물론 나중에 문제가 100% 생기지만) 내가 원하는 데이터의 시작 단어와 끝 단어를 기준으로 문자열을 잘라내어, json 처럼 취급했다.

html의 inline javacript로 정보가 담겨 있다.
그래서 이래저래 고생하긴 했지만, 깔끔하게 json을 뽑아낼 수 있었다. 뽑아낸 만화 및 에피소드 정보는 자체 API를 만들어 사용할 수 있게 했다. 이는 아래와 같다.
- comics: http://kb.update.sh/lezhin-rss/api/comics
- episodes: ;
데이터 저장 및 업데이트
얻어온 정보는 sqlite를 이용하여 저장해놓고 사용하기로 했다. 이는 Flask-SQLAlchemy를 통해 ORM으로 단순하게 해결했다. 만화와 에피소드에 맞는 모델만 적절하게 정의해놓으면 끝이었다.
문제는 업데이트에 있었다. 그냥 반복문을 돌면서 전체 만화와 에피소드를 가져오는 것은 시간이 너무 오래 걸렸다. (이 당시 만화는 약 700개, 에피소드는 약 60,000화 이상이었다. 당연히 오래 걸린다.) 전체 만화와 에피소드 목록을 가져오는데 약 13분이 소요되었다.
대부분의 시간 소요는 네트워크 I/O 때문에 발생할 것이라 예측하고 multiprocessing을 이용해서 8 프로세스로 동작하게 했다. 결과는 만족. 2분 정도만에 모든 만화와 에피소드 목록을 가져올 수 있었다.
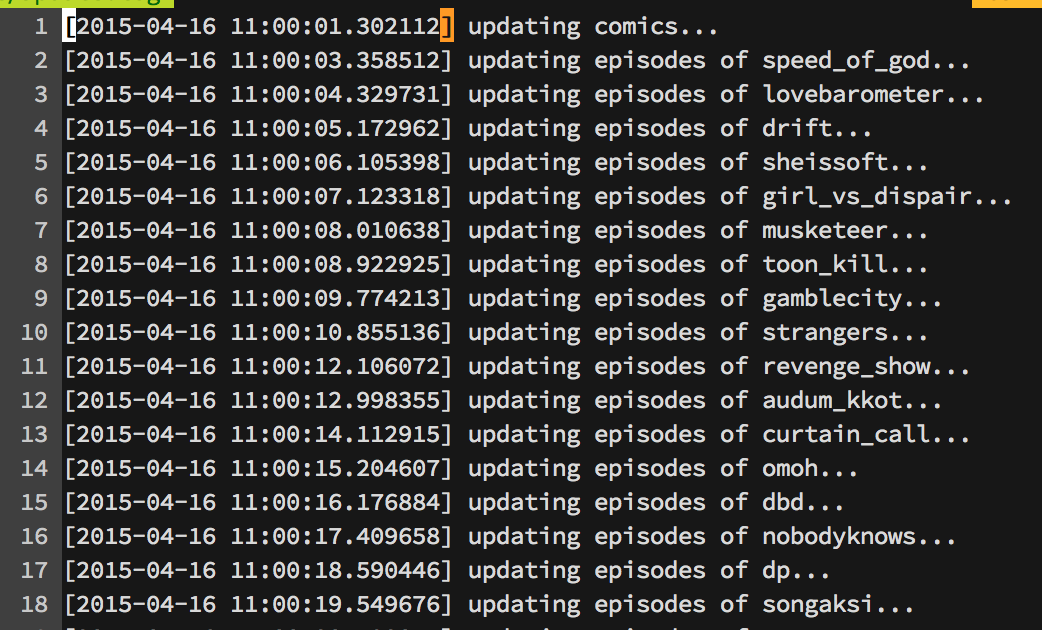
만화 및 에피소드를 가져온다. 8 프로세스로 동작해서 약 2분만에 모든 만화와 에피소드 정보를 가져올 수 있다.
또, 레진코믹스의 웹 사이트 구조가 변경될 경우 업데이트가 정상적으로 이루어지지 않을 것이다. 이 경우를 판단하기 위해 업데이트 중 파싱 에러가 발생할 경우 나에게 에러 정보를 gmail을 통해 보내도록 만들어 놓았다. 이젠 간단하게 cron에 매 시간 정각에 동작하도록 추가하면 끝.
구독정보 생성
만화 및 에피소드 정보를 모두 가져왔으니, 이젠 이를 Atom과 RSS로 만들어서 제공하자. Atom 1.0의 경우Flask는 Werkzeug를 통해 동작하므로, Werkzeug의 Atom Syndication 문서를 통해 구현하면 된다. RSS 2.0은 PyRSS2Gen을 통해 제공하기로 했다.
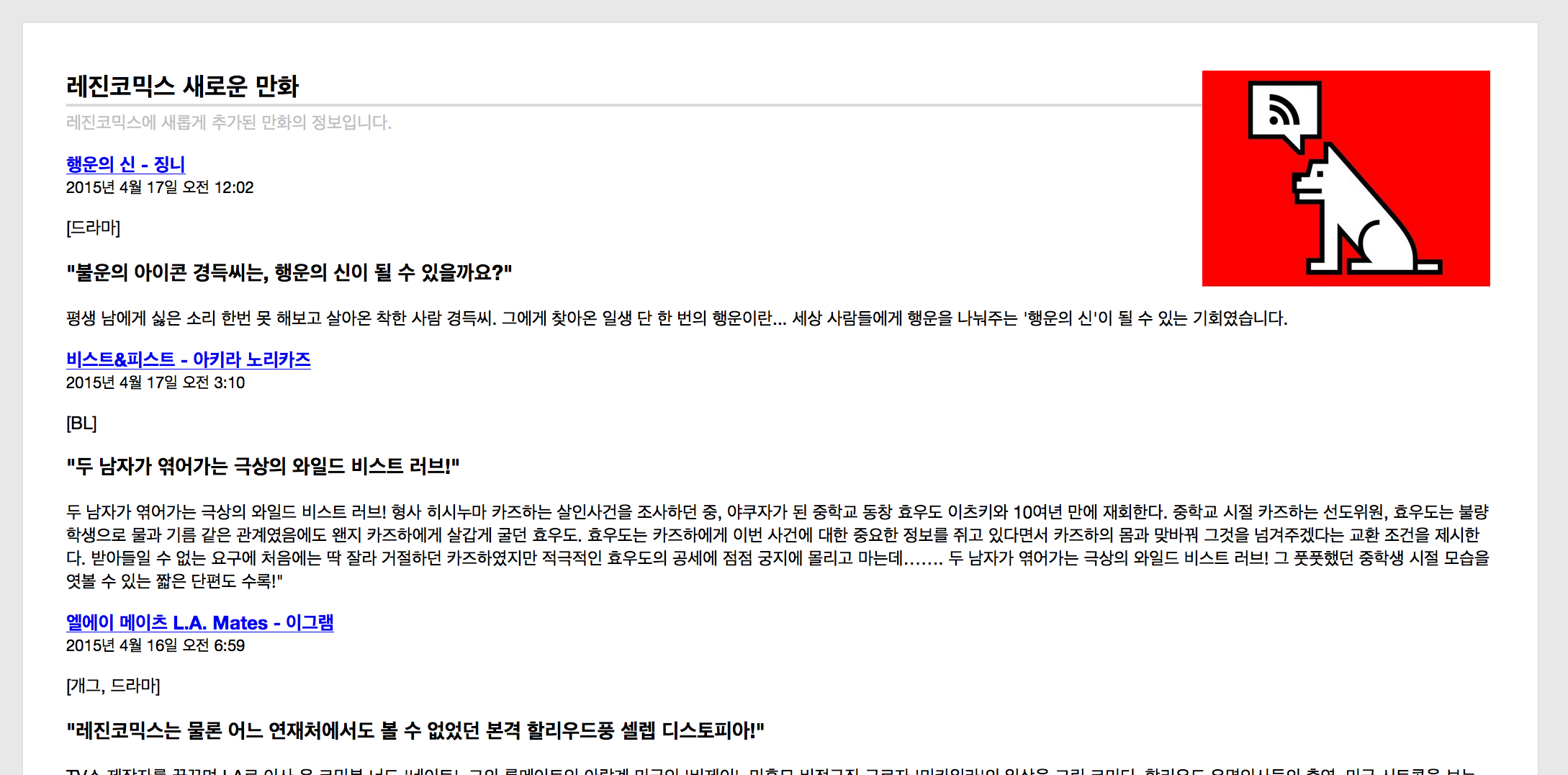
Firefox로 열어본 Atom 구독정보
메인페이지 제작
사실 위의 작업보단 웹에서 구독할 수 있는 만화들을 보여주는 메인페이지 제작이 더 큰일이었다. 왜냐하면 내가 웹을 잘 못하니까… 그래서 대충 대충 간단하게 끝냈다.
기존 레진코믹스 로고를 이용해 간단하게 만들어본 RSS 개(…)
우선 JQuery와 Bootstrap을 써서 간단하게 틀을 잡고, 제목대로 만화를 정렬해서 페이지당 50개씩 보여주기로 했다. 이 작업을 하면서 처음으로 Flask-SQLAlchemy에서 pagenate라는걸 사용할 수 있다는 것을 알았다. 여태까지 페이지 작업하는 코드를 일일히 짜줬는데, 이 녀석이면 간단하게 해결 할 수 있다.
검색같은 경우에는 처음에는 Whoosh 사용을 고려했지만, 한글 설정이 미묘했고, 굳이 많지 않은 제목과 작가 검색에 검색 엔진까지 붙여 사용할 필요성을 느끼지 못해 사용하지 않았다.
결론
결과적으로 사이트는 간단하게 완성할 수 있었다. 처음 목표로 했던 기능은 모두 구현했으므로, 특별히 이상이 생기지 않는 한 더 이상 건드릴 일은 없을 것이다.
본 프로젝트의 전체 소스코드는 https://git.update.sh/nesswit/lezhin-rss/tree/master 에서 확인할 수 있다. 만약 이 프로젝트를 클론해서 직접 실행해보고 싶다면, app/db 폴더를 생성하고, update.py 파일에서 mail 보내는 부분을 모두 지운 뒤, update.py를 실행시켜 db를 생성하고, debug.py 파일로 임시 웹서버를 실행해보면 된다.